
Writer monads for knowledge tracking in OCaml

Tracking knowledge across large areas of a codebase is a fairly common task. Keeping track of whether or not some cache miss happens when loading files is an example of this — you could want to track this in a metric. If we model knowledge monoidally, we can use a writer monad to track this knowledge without boilerplate in a simple and threadsafe manner.
Feel free to skip the background section if you don't care how this problem came up in a real project.
Background
The Mina Protocol uses zk-SNARKs to compress the blockchain down to a constant size. These SNARKs are proof objects certifying that some computation has been run correctly. Some nodes in the network create these SNARKs and others verify them. To create a SNARK one needs to have a specific large proving key, and to verify a SNARK one needs to a specific small verification key. These proving and verification keys are indexed by the SNARK logic itself. In other words, if any computation changes then the proving and verifying keys need to change. In other other words, whenever some code is changed in the SNARK circuit during the development of Mina, both proving keys and verification keys must be regenerated. Key generation also involves some randomness.
We want developers to be productive and so we want proving and verification key generation to happen transparently at build time.
Naively, one can just always regenerate all proving and verification keys every build, but this has some drawbacks: (1) As randomness is involved during key generation, keys created from different builds will be incompatible. For example, you wouldn't be able to connect to a live network that was built on CI with some local branch of code, even though when you haven't touched any SNARK logic that would invalidate the keys. (2) Also, key generation is slow so we'd like to skip that step if possible.
A nice solution to this would be to remove the randomness from key generation under certain conditions. This may be done by adding some debug branch through the code that generates. Unfortunately, it turned out to be quite a bit of work to get rid of all the randomness in the key generation logic. It's enough work that we decided to punt on it temporarily.
Another solution is to introduce a series of layered caches that would be placed in front of key-generation in the key-loading process. To load keys in Mina, the following process is followed:
- Try to load the keys from a manual override path
- Try to load the keys from the normal installation path
- Try to load the keys from an S3 installation path
- Try to load the keys from S3
- Try to load the keys from the auto-generation path
- Auto-generate the keys
- Store the keys in the auto-generation path (only if the keys were auto-generated)
- Store the keys in S3 (only if the keys were auto-generated)
To further complicate things, we need to track the outcome of the key generation process and propagate it to various interested observers for legacy reasons.
Finally, we're sufficiently motivated.
Simplified Model
The following is a simplified model of the problem. In reality, there may be several more places where loading occurs:
module Action : sig type 'a tend
Actions are what happens when you invoke a load-or-generate function.
module A (Intf: sig type elem1 type elem2 type t val load_or_gen_a1 : unit -> elem1 Action.t val load_or_gen_a2 : unit -> elem2 Action.t val build : elem1 -> elem2 -> tend) = struct include Intf let load_or_gen_a = let open Deferred.Let_syntax in let* a1 = loadOrGenA1 () in let+ a2 = loadOrGenA2 () in build a1 a2end
In one spot we load a1 and a2 to create an A.t.
module B = struct type t let load_or_gen_b : unit -> t Action.tend
In another, we load a B.t.
module Subroutine = struct let load_or_gen () = let open Deferred.Let_syntax in let* a = load_or_gen_a () in let+ b = load_or_gen_b () in (a, b)end
Finally we load A.t and B.t together.
To model whether or not generation has occurred:
module Track_generated = struct type t = [`Generated_something | `Cache_hit]end
The task is to somehow incorporate generated knowledge into the output of load_or_gen in a clean way.
In this model, actions are the asynchronous monad. Let's assume we're using Jane Street's Async library and then implement Action as follows:
module Action = struct type 'a t = 'a Deferred.tend
Tracking Knowledge v1
A naive way to track whether or not generation has occurred is to introduce some sort of global mutable state.
module Global_mutable_state = struct let generation_occurred = let state = ref `Cache_hit in fun () -> state := `Generated_somethingend
Then in load_or_gen_a1, load_or_gen_a2, and load_or_gen_b we need to call generation_occurred () whenever necessary.
This is easy to implement, but it's a very terrible solution! Global mutable state means we need to be careful about concurrent writes. We also need to make sure we don't forget to call this function if we ever introduce a new place load_or_gen leaf in the call graph. It's error-prone and brittle.
Extending our knowledge model
The concept of knowledge has an interesting property: Once I know a, when presented with new information b I'll never un-know a. As a consequence, knowledge gives rise to a semilattice.
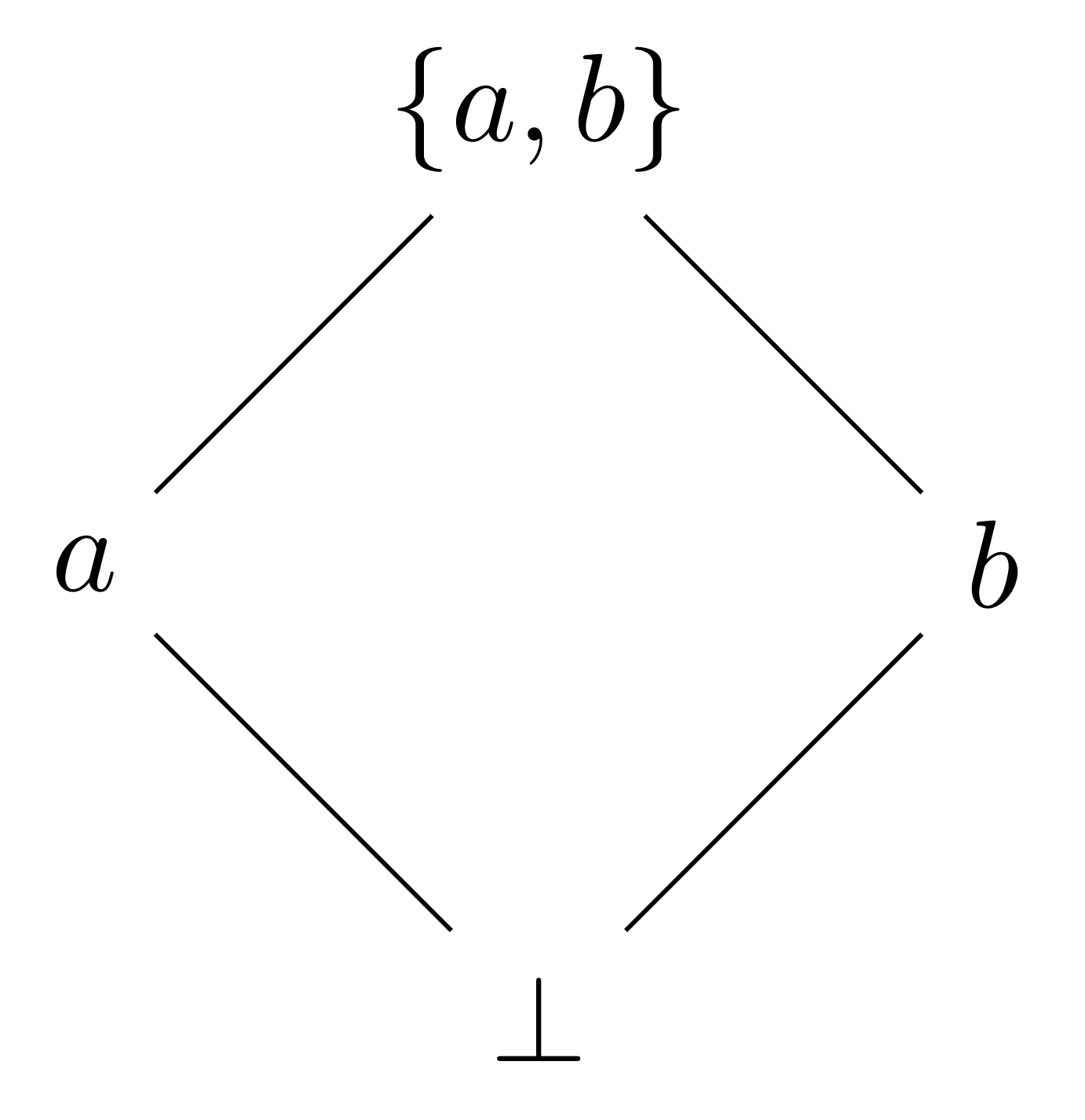
At the bottom, I know nothing or . Afterward, I can learn about or , and once I see the other one I know both .
This means we can implement a well-defined commutative, associative, idempotent binary operation that incorporates new knowledge. And in this case, since we don't act when Cache_hit, we can treat Cache_hit as our identity or bottom state, and Generated_something is our top state.
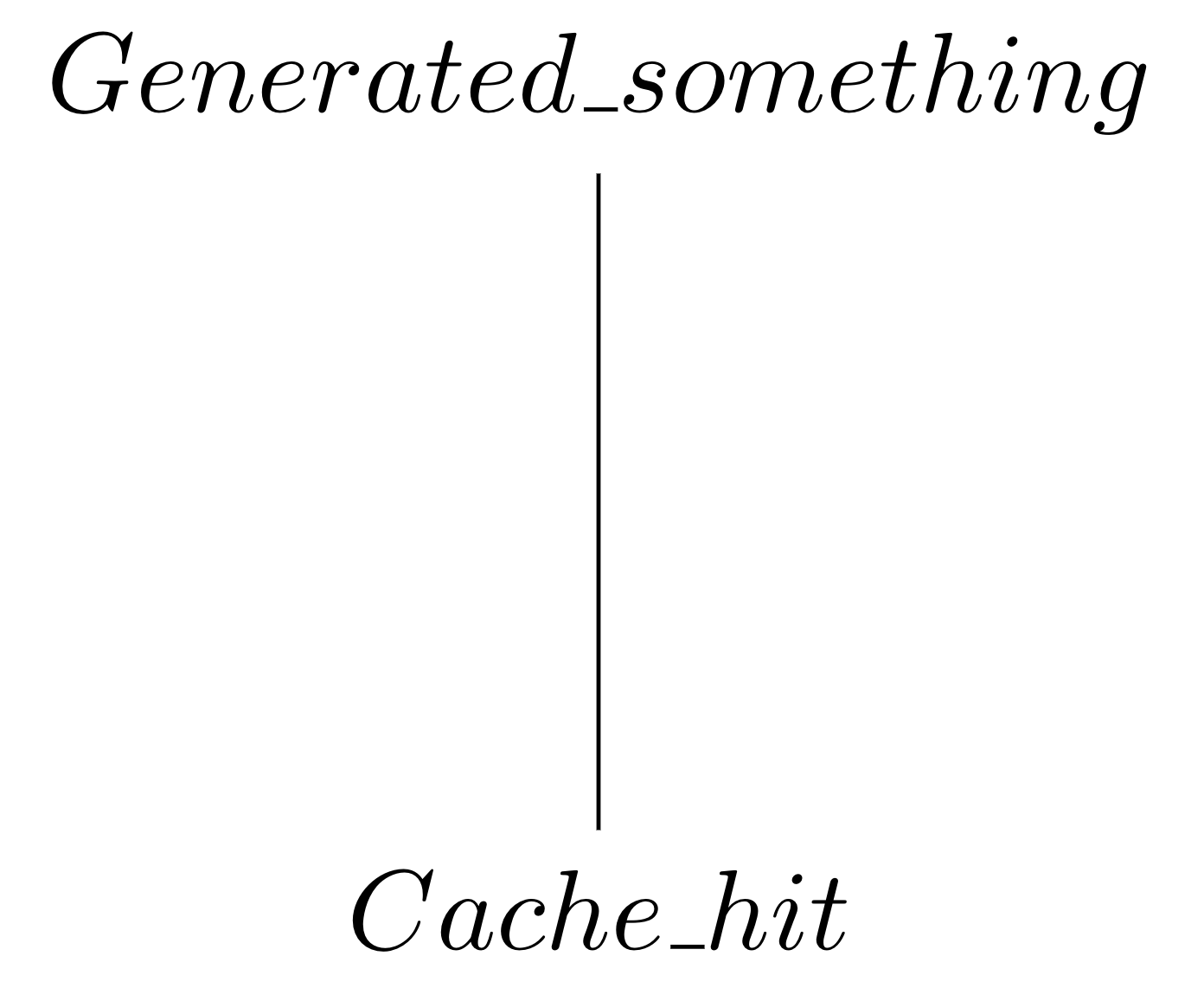
module Track_generated = struct type t = [`Generated_something | `Cache_hit] let bottom = `Cache_hit (* In Haskell, we'd provide a Monoid instance and use * <>, but OCaml uses <> for does-not-equal-to *) let (+) x y = match (x, y) with | (`Generated_something, _) | (_, `Generated_something) -> `Generated_something | (`Cache_hit, `Cache_hit) -> `Cache_hitend
Tracking Knowledge v2
Now we can ditch our global mutable state, and instead change our actions to also give us the new knowledge about Track_generated.t:
module Action = struct type 'a t = ('a * Track_generated.t) Deferred.tend
Then we update load_or_gen_a and load_or_gen to thread through the knowledge. Here's what load_or_gen_a would look like afterwards:
let load_or_gen_a () = let* (a1, t1) = load_or_gen_a1 () in let+ (a2, t2) = load_or_gen_a2 () in (build a1 a2, t1 + t2)
A better solution! We've eliminated global mutable state, so we've solved the concurrency problem. This is parallelizable since knowledge aggregation is commutative and associative. Unfortunately, we still have a bunch of boilerplate that we can't forget to add. And it's still brittle: The type-system will remind us to remember that actions have a tupled result, but we need to rely on warnings at best to remember to join together all of our knowledge.
Writer Monad
The writer monad wraps computation alongside some monoidal value. Traditionally, this is used in a language like Haskell to aggregate logs — some call it the logging monad. However, we're free to use any monoid here. Monoids are values that have an identity and an associative binary operation — just like that we've described above.
For reference, here's an OCaml implementation of a writer monad:
module type Monoid_intf = sig type t val empty : t val (+) : t -> t -> tendmodule Writer (M : Monoid) = struct type 'a t = 'a * M.t include Monad.Make (struct type nonrec 'a t = 'a t let return x = (x, M.empty) let map = `Define_using_bind let bind (a, m1) ~f = let open M in let (b, m2) = f a in (b, m1 + m2) end)end
We can layer Writer on Track_generated under the async monad to get a monad that both tracks knowledge and runs code concurrently.
module With_track_generated = struct type 'a t = {data: 'a, dirty: Track_generated.t}endmodule Deferred_with_track_generated = struct type 'a t = 'a With_track_generated.t Deferred.t include Monad.Make (struct type nonrec 'a t = 'a t let return x = Deferred.return {With_track_generated.data= x; dirty= Track_generated.empty} let map = `Define_using_bind let bind t ~f = let open Deferred.Let_syntax in let* {With_track_generated.data; dirty= dirty1} = t in let+ {With_track_generated.data= output; dirty= dirty2} = f data in { With_track_generated.data= output ; dirty= Track_generated.(dirty1 + dirty2) } end)end
Tracking Knowledge v3
This time, we'll change Action once more:
module Action = struct type 'a t = 'a Deferred_with_track_generated.tend
Then we'll get compilation errors until we change our leaf load_or_gen functions to return that initial Track_generated.t. And we're done! We don't have to change load_or_gen_a or load_or_gen_b at all other than opening this monad instead of Deferred.
This is the best solution! There is no global mutable state. There is no boilerplate. Our code is clean and knowledge propagation is neatly handled for you. If later more load_or_gen functions are introduced, the type system will demand that the author remembers to send a Track_generated.t with the output.
Summary
Writer monads provide a boilerplate-free, thread-safe, non-error-prone way to propagate knowledge through large swaths of a codebase. In Mina, we used the Deferred with_track_generated monad to propagate knowledge that some generation occurs to give developers a transparent way to keep their code as compatible as possible with other builds to make them more productive.
Thank you Christina Lee and Omer Zach for your thoughtful reviews on this post!